Useful Tips To Speed Up Your MySQL Queries
If you are interested in how to create fast MySQL queries, this article is for you
- Use persistent connections to the database to avoid connection overhead.
- Check all tables have PRIMARY KEYs on columns with high cardinality (many rows match the key value). Well,`gender` column has low cardinality (selectivity), unique user id column has high one and is a good candidate to become a primary key.

- All references between different tables should usually be done with indices (which also means they must have identical data types so that joins based on the corresponding columns will be faster). Also check that fields that you often need to search in (appear frequently in WHERE, ORDER BY or GROUP BY clauses) have indices, but don’t add too many: the worst thing you can do is to add an index on every column of a table (I haven’t seen a table with more than 5 indices for a table, even 20-30 columns big). If you never refer to a column in comparisons, there’s no need to index it.
- Using simpler permissions when you issue GRANT statements enables MySQL to reduce permission-checking overhead when clients execute statements.
- Use less RAM per row by declaring columns only as large as they need to be to hold the values stored in them.
- Use leftmost index prefix — in MySQL you can define index on several columns so that left part of that index can be used a separate one so that you need less indices.
- When your index consists of many columns, why not to create a hash column which is short, reasonably unique, and indexed? Then your query will look like:
- SELECT *
- FROM table
- WHERE hash_column = MD5( CONCAT(col1, col2) )
- AND col1=‘aaa’ AND col2=‘bbb’;
- Consider running ANALYZE TABLE (or myisamchk –analyze from command line) on a table after it has been loaded with data to help MySQL better optimize queries.
- Use CHAR type when possible (instead of VARCHAR, BLOB or TEXT) — when values of a column have constant length: MD5-hash (32 symbols), ICAO or IATA airport code (4 and 3 symbols), BIC bank code (3 symbols), etc. Data in CHAR columns can be found faster rather than in variable length data types columns.
- Don’t split a table if you just have too many columns. In accessing a row, the biggest performance hit is the disk seek needed to find the first byte of the row.
- A column must be declared as NOT NULL if it really is — thus you speed up table traversing a bit.
- If you usually retrieve rows in the same order like expr1, expr2, …, make ALTER TABLE … ORDER BY expr1, expr2, … to optimize the table.
- Don’t use PHP loop to fetch rows from database one by one just because you can — use IN instead, e.g.
- SELECT *
- FROM `table`
- WHERE `id` IN (1,7,13,42);
- Use column default value, and insert only those values that differs from the default. This reduces the query parsing time.
- Use INSERT DELAYED or INSERT LOW_PRIORITY (for MyISAM) to write to your change log table. Also, if it’s MyISAM, you can add DELAY_KEY_WRITE=1 option — this makes index updates faster because they are not flushed to disk until the table is closed.
- Think of storing users sessions data (or any other non-critical data) in MEMORY table — it’s very fast.
- For your web application, images and other binary assets should normally be stored as files. That is, store only a reference to the file rather than the file itself in the database.
- If you have to store big amounts of textual data, consider using BLOB column to contain compressed data (MySQL’s COMPRESS() seems to be slow, so gzipping at PHP side may help) and decompressing the contents at application server side. Anyway, it must be benchmarked.
- If you often need to calculate COUNT or SUM based on information from a lot of rows (articles rating, poll votes, user registrations count, etc.), it makes sense to create a separate table and update the counter in real time, which is much faster. If you need to collect statistics from huge log tables, take advantage of using a summary table instead of scanning the entire log table every time.
- Don’t use REPLACE (which is DELETE+INSERT and wastes ids): use INSERT … ON DUPLICATE KEY UPDATE instead (i.e. it’s INSERT + UPDATE if conflict takes place). The same technique can be used when you need first make a SELECT to find out if data is already in database, and then run either INSERT or UPDATE. Why to choose yourself — rely on database side.
- Tune MySQL caching: allocate enough memory for the buffer (e.g. SET GLOBAL query_cache_size = 1000000) and define query_cache_min_res_unit depending on average query resultset size.
- Divide complex queries into several simpler ones — they have more chances to be cached, so will be quicker.
- Group several similar
INSERTs in one longINSERTwith multipleVALUESlists to insert several rows at a time: quiry will be quicker due to fact that connection + sending + parsing a query takes 5-7 times of actual data insertion (depending on row size). If that is not possible, useSTART TRANSACTIONandCOMMIT, if your database is InnoDB, otherwise useLOCK TABLES— this benefits performance because the index buffer is flushed to disk only once, after allINSERTstatements have completed; in this case unlock your tables each 1000 rows or so to allow other threads access to the table. - When loading a table from a text file, use LOAD DATA INFILE (or my tool for that), it’s 20-100 times faster.
- Log slow queries on your dev/beta environment and investigate them. This way you can catch queries which execution time is high, those that don’t use indexes, and also — slow administrative statements (like OPTIMIZE TABLE and ANALYZE TABLE)
- Tune your database server parameters: for example, increase buffers size.
- If you have lots of DELETEs in your application, or updates of dynamic format rows (if you have VARCHAR, BLOB or TEXT column, the row has dynamic format) of your MyISAM table to a longer total length (which may split the row), schedule running OPTIMIZE TABLE query every weekend by crond. Thus you make the defragmentation, which means more speed of queries. If you don’t use replication, add LOCAL keyword to make it faster.
- Don’t use ORDER BY RAND() to fetch several random rows. Fetch 10-20 entries (last by time added or ID) and make array_random() on PHP side. There are also other solutions.
- Consider avoiding using of HAVING clause — it’s rather slow.
- In most cases, a DISTINCT clause can be considered as a special case of GROUP BY; so the optimizations applicable to GROUP BY queries can be also applied to queries with a DISTINCT clause. Also, if you use DISTINCT, try to use LIMIT (MySQL stops as soon as it finds row_count unique rows) and avoid ORDER BY (it requires a temporary table in many cases).
- When I read “Building scalable web sites”, I found that it worth sometimes to de-normalise some tables (Flickr does this), i.e. duplicate some data in several tables to avoid JOINs which are expensive. You can support data integrity with foreign keys or triggers.
- If you want to test a specific MySQL function or expression, use BENCHMARK function to do that.
 How to Start a Functioning Website Under Thirty Dollars 2021?
How to Start a Functioning Website Under Thirty Dollars 2021?  CSS3 Powered jQuery Image Slider for 2D or 3D transitions – Flux Slider
CSS3 Powered jQuery Image Slider for 2D or 3D transitions – Flux Slider  Now Easy to Convert Websites Into Mobile Quickly: Mobilize.js
Now Easy to Convert Websites Into Mobile Quickly: Mobilize.js  The HTML5 Time Element Is Back and Better Than Ever
The HTML5 Time Element Is Back and Better Than Ever  Mozilla Introduce Firefox 9, with Speed and less memory improvements
Mozilla Introduce Firefox 9, with Speed and less memory improvements 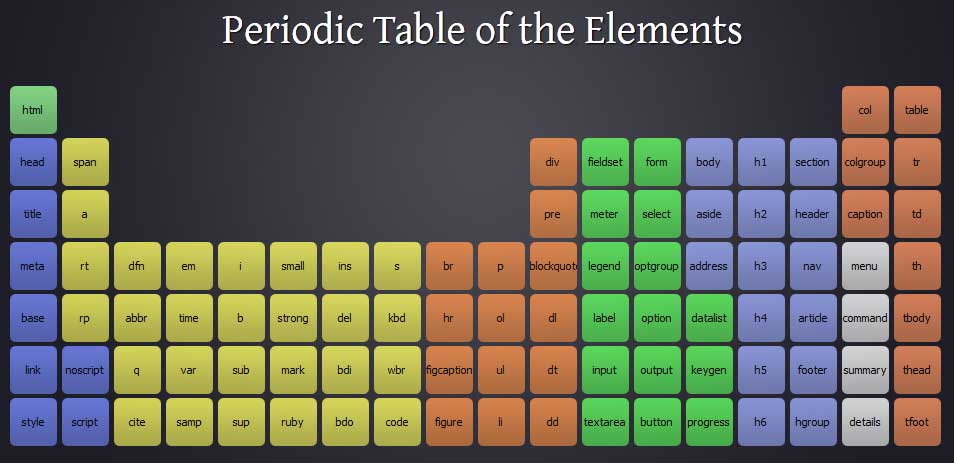 Periodeic table of HTML5 Elements, arrange by type.
Periodeic table of HTML5 Elements, arrange by type.